Technical FAQs for "PrizmDoc Viewer"

Data volumes are increasing at rapid speed. As noted by Forbes, there are 16 million text messages, 156 million emails, and 154,200 video calls made every minute. Human curiosity is keeping pace, with search engines now processing more than five billion inquiries every day.
Along with instant information gratification, a data-driven world gives rise to new concerns. When everything is collected, everything becomes evidence. Emails, documents, images, text messages, and other data types now form the basis of both criminal and civil legal actions. What’s more, they’re subject to the increasingly rigorous process of eDiscovery: identifying, cataloging, and sharing key documents as required to ensure lawyers on both sides of a case have access to the same information.
The result? Firms need a better way to practice law and create order across multiple data sources. The solution? Top notch eDiscovery features in tools and applications. Not sure what passes the bar? Look for these five must-have features.
File Format Support
The legal profession is evolving. According to The Counsel Network, while this has prompted some pushback from more traditionalist firms, these changes present the unique opportunity to redesign the delivery of legal services.
One harbinger of change? File formats. From emails to text messages, accounting spreadsheets to Word documents, and image formats such as TIFF, JPEG, CAD, CAM, PSD, and PCX, the sheer number of file types lawyers must be able to locate — and view — during the eDiscovery process makes it critical to leverage a solution that both integrates with existing applications and provides single-click support for virtually any image or document type.
Full Text Search
Conducting eDiscovery for clients often requires a wide-ranging search through operational and organizational data across multiple sources. Keyword-driven, full text searches simplify this process by quickly identifying relevant documents; when combined with document-viewer interactivity, lawyers can easily determine context and confidently include or exclude files.
Annotation Ability
The biggest challenge for eDiscovery tools in law firms? According to Legaltech news, it’s getting lawyers to reliably use these solutions. Familiarity plays a role, too. Staff comfortable with current processes are often resistant to making the switch. Lack of features is the other caveat. If attorneys can’t easily annotate critical files with their team’s particular scheme of color-coding, notes, or shorthand, they’ll actively avoid using new eDiscovery tools.
Best bet? Leverage an eDiscovery viewer that provides in-app review, commenting, and markup capabilities across multiple file types for collaboration and sharing in addition to preserving unaltered versions of the original document.
Robust Redaction
Traditionally redaction is a labor-intensive process that involves manually redacting sensitive information by blacking it out by hand. Improperly redacted files could put confidential data at risk, not to mention the possibility of federal and regional fines associated with inadvertent disclosure. Fines like these can cost legal organizations hundreds of thousands of dollars. In addition, manual redaction inhibits the productivity of an organization, ultimately impacting its profitability. Simply put, this process has become inefficient, risky, and costly. There’s a better way. Native redaction tools enable parties to streamline the redaction process to reduce time and costs associated with eDiscovery. The right tool can increase accuracy and reduce the risk of human error.
Technology like this allows lawyers to focus their time in more valuable ways rather than going through documents manually applying redactions. Native redaction makes it possible for lawyers to “burn in” their alterations by effectively removing the underlying image mask replacing it with a custom markup. These tools also empower teams to view and create redactions across multiple files types without the need for application switching.
Digital Rights Management (DRM)
Who has access to documents? What permissions do they have? Digital rights management (DRM) is now a key aspect of legal eDiscovery. While firms are often required to disclose critical information, native DRM integration lets them set limits on printing, saving, navigation, and document sharing outside corporate firewalls.
The Total Package
Accusoft’s PrizmDoc Viewer is your all-in-one eDiscovery solution. With support for hundreds of file formats, full text, annotation, redaction, and DRM capabilities, PrizmDoc Viewer offers easy integration and complete customization to help law firms bring order to eDiscovery chaos.

Whether your clients are working on processing a loan or gathering financial data for a consumer’s credit request, lending is a complex process that is only getting more complicated in this fast-paced digital era. Your application helps financial institutions address a variety of pain points, but is it solving the one that’s most pressing today?
Consumers of financial institutions are required to submit various forms when applying for a line of credit or loan. Does your financial application make it easy for lenders to review and approve these documents? Some applications require downloading a file to a third party service like Word. However, this can be tedious – a process that wastes time and complicates the collaboration process for your clients.
Document Viewing Within Your Application
Financial institutions are searching for a standard procedure to help them view and collaborate on borrower histories. Due to time restrictions, they need a process that simplifies functions like search, annotation, file conversion, and more.
What if there was a way to view a variety of different document types within your own application? Imagine a lender uploading the forms into your product, viewing customer data all in one place, sending information through various approval routes, and searching for the information they need in seconds.
With Accusoft’s unique software development kits (SDKs) and application programming interfaces (APIs), you can integrate a variety of different features into your product to help lenders process credit applications faster. They can view consumer data within files, identify data in form fields, and extract borrower information into a database.
Accusoft has a solution that can greatly reduce your coding time. PrizmDoc Viewer is a highly versatile document viewer that handles a variety of issues typically encountered in loan origination and credit applications. Easily embeddable into financial software, PrizmDoc Viewer enables you to worry less about code and focus more on your clients’ pain points.
A Pre-Built Solution to Enhance Your Product
When you integrate PrizmDoc Viewer into your application, your lenders can view dozens of file formats, including the text files most commonly associated with loan processing, without leaving the native program. For example, if a lender needs to view an Excel file, they can view it within your application without opening Excel itself and exiting your application.
In addition, PrizmDoc Viewer has search functionality that enables you to find information quickly and efficiently. When you search a document for specific information, PrizmDoc Viewer uses hit highlighting to locate the information in seconds – even if the document is thousands of pages long.
With these unique features already in PrizmDoc Viewer, it’s easy to see why Accusoft products are trusted by major brands. Make sure your clients are getting the versatility they need by delivering a customized solution for them. When you integrate PrizmDoc Viewer into your application, you’re saving coding time and creating a more powerful solution for your customers.
What pain points can you solve for your customers? Create a more versatile solution for their needs with a document viewer that streamlines their lending process. If you want to learn more about financial lending integrations, contact us today.
Text-to-speech (also known as speech synthesis) is the artificial production of human speech. It is most commonly used to allow people with visual impairments or reading disabilities to listen to written words. Thanks to the Speech Synthesis API, which is natively supported in modern browsers, text-to-speech functionality can easily be integrated into a web application. In this post, I will outline how to add it to the PrizmDoc Viewer with a few simple steps.

1. Add a Listen Menu
Add the code below to viewer-assets/templates/viewerTemplate.html to add a “Listen” menu to the viewer containing a play, pause, and stop button. You can add this code after the div containing “data-pcc-nav-tab=”esign”” to show the “Listen” tab to the right of the existing “E-Sign” tab.
<div class="pcc-tab" data-pcc-nav-tab="listen" data-pcc-removable-id="listenTab">
<div class="pcc-tab-item"><span class="pcc-icon pcc-icon-listen"></span> <%= listen %></div>
<div class="pcc-tab-pane">
<div class="pcc-left">
<button class="pcc-icon pcc-disabled" title="<%= stop %>" data-pcc-listen="stop">
<span>◼</span>
</button>
<button class="pcc-icon pcc-disabled" title="<%= pause %>" data-pcc-listen="pause">
<span>❚❚</span>
</button>
<button class="pcc-icon pcc-disabled" title="<%= play %>" data-pcc-listen="play">
<span>►</span>
</button>
</div>
</div>
</div>To show an icon on the new “Listen” tab, create a new file (named listen.svg) in the viewer-assets/icons/svg folder, and add the SVG below to the file. This icon is referenced as pcc-icon-listen in the HTML template code above.
<svg width="52" height="52" ><br /><br />
<path d="m21,20l10,7l-10,7l0,-14z"/><br />
<path d="m38.681,17.159c-0.694,-0.947 -1.662,-2.053 -2.724,-3.116s-2.169,-2.03 -3.116,-2.724c-1.612,-1.182 -2.393,-1.319 -2.841,-1.319l-15.5,0c-1.378,0 -2.5,1.121 -2.5,2.5l0,27c0,1.378 1.122,2.5 2.5,2.5l23,0c1.378,0 2.5,-1.122 2.5,-2.5l0,-19.5c0,-0.448 -0.137,-1.23 -1.319,-2.841zm-4.138,-1.702c0.959,0.959 1.712,1.825 2.268,2.543l-4.811,0l0,-4.811c0.718,0.556 1.584,1.309 2.543,2.268zm3.457,24.043c0,0.271 -0.229,0.5 -0.5,0.5l-23,0c-0.271,0 -0.5,-0.229 -0.5,-0.5l0,-27c0,-0.271 0.229,-0.5 0.5,-0.5c0,0 15.499,0 15.5,0l0,7c0,0.552 0.448,1 1,1l7,0l0,19.5z"/><br />
</svg>The HTML template code above also references some text. All viewer text is stored in the language file, viewer-assets/languages/en-US.json. You will need to add the following new terms to the language file.
"listen": "Listen",
"stop": "Stop",
"pause": "Pause",
"play": "Play",You will need to build the viewer after making the above changes, and copy the output dist/viewer-assets files over the viewer-assets files of your web page. Steps for building the viewer are in the README file of each installed PrizmDoc Viewer sample. In summary, you will need to run “npm install” and then run “gulp build”. You will need to copy all of the files in the viewer-assets folder except Gulpfile.js and package.json to a “src” folder in the viewer-assets folder first.
2. Reference the UI and Enable in Supported Browsers
The code in this step and the following steps can be added to the function where you are calling the pccViewer method to create the viewer. For example, in the webforms sample you would add it to the embedViewer function in Default.aspx.
Add variables to reference the stop, pause, and play buttons. Enable the play button only if the browser supports Speech Synthesis. The Speech Synthesis API is natively supported by the latest versions of Chrome, Firefox, Edge, and Safari, but is not supported in Internet Explorer 11 and many mobile browsers.
function embedViewer(options) {
var viewer = $('#viewer1').pccViewer(options);
var $speechStop = $('#viewer1').find("[data-pcc-listen=stop]");
var $speechPause = $('#viewer1').find("[data-pcc-listen=pause]");
var $speechPlay = $('#viewer1').find("[data-pcc-listen=play]");
if ('speechSynthesis' in window) {
$speechPlay.prop('disabled', false).removeClass('pcc-disabled');
}
3. Implement Speaking
Add the play button click event handler below. Clicking the play button will begin playing all of the pages starting at the current page, or resume if playing had already started and was paused.
var startedPlaying = false;
$speechPlay.on('click', function (ev) {
$speechStop.prop('disabled', false).removeClass('pcc-disabled');
$speechPause.prop('disabled', false).removeClass('pcc-disabled');
$speechPlay.prop('disabled', true).addClass('pcc-disabled');
if (startedPlaying === false) {
startedPlaying = true;
play(viewer.viewerControl.getPageNumber());
}
else {
window.speechSynthesis.resume();
}
});Add the play and stop functions below. The play function requests the text of a page and uses it to create a SpeechSynthesisUtterance. The speechSynthesis.speak method is called to initiate the speaking. When completed, the onend event handler is used to play the next page, unless the last page has been played. In that case, the stop function is called to reset the state to allow playing again.
function play(pageNumber) {
viewer.viewerControl.setPageNumber(pageNumber);
viewer.viewerControl.requestPageText(pageNumber).then(
function(pageText) {
// Lines in documents may end in carriage returns. Remove them from
// the text to avoid pauses in the speech.
pageText = pageText.replace(/(rn|n|r|_)/gm, ' ');
var utterance = new window.SpeechSynthesisUtterance(pageText);
// To work around a known bug in Chrome with onend not always firing,
// add a global reference to the utterance
// https://bugs.chromium.org/p/chromium/issues/detail?id=509488
window.utterances = [];
window.utterances.push(utterance);
utterance.onend = function () {
if (startedPlaying) {
if (pageNumber >= viewer.viewerControl.getPageCount()) { stop();
}
else {
play(pageNumber + 1);
}
}
};
window.speechSynthesis.cancel();
window.speechSynthesis.speak(utterance);
}
);
}
function stop() {
startedPlaying = false;
window.speechSynthesis.cancel();
$speechStop.prop('disabled', true).addClass('pcc-disabled');
$speechPause.prop('disabled', true).addClass('pcc-disabled');
$speechPlay.prop('disabled', false).removeClass('pcc-disabled');
}
4. Implement Pausing
The speechSynthesis.pause method pauses the speech. Add the following pause button click event handler after the previously added play button click event handler.
$speechPause.on('click', function (ev) {
$speechPause.prop('disabled', true).addClass('pcc-disabled');
$speechPlay.prop('disabled', false).removeClass('pcc-disabled');
window.speechSynthesis.pause();
});
5. Implement Stopping
To implement stopping of the speech, add the following stop button click event handler after the previously added Pause button click event handler.
$speechStop.on('click', function (ev) {
stop();
});Once you’ve followed these steps to integrate text-to-speech functionality into your PrizmDoc Viewer, your users can start listening to documents with the click of a button. For more information on what you can do with PrizmDoc Viewer, visit the documentation.
If the people using your web application need to view, search, redact, or annotate documents right in their browser, PrizmDoc Viewer is an amazing option. It lets you present Office, PDF, TIFF, email, and many other kinds of documents as part of your web application. Check out some of the demos if you’ve never seen it in action.
To make all of this possible, there are basically two sides to the PrizmDoc Viewer architecture:
- The HTML viewer itself, running in the browser
- A powerful backend which converts documents, page by page, to SVG for viewing in the browser
Your web server sits between these two, acting as a proxy for the viewer to ask the backend for the pages it needs to display:
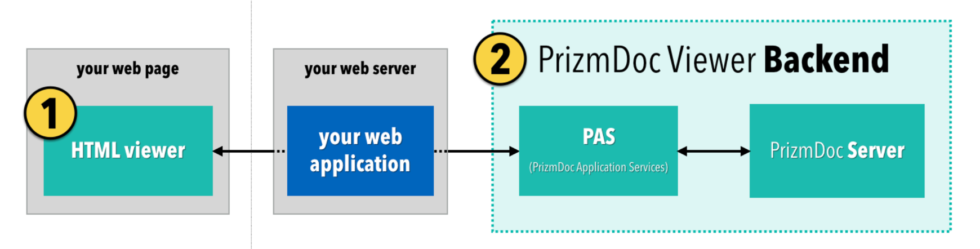
One of the advantages of this architecture is that we can deliver the first page of the document as soon as it’s ready, even while the rest of the document is still being converted. However, setting up and maintaining the backend is not trivial.
Fortunately, Accusoft can handle all of that for you with PrizmDoc Cloud. Sign up, get an API key, and simply connect your web application to our already-running, fully-managed PrizmDoc Viewer backend. It’s a great option, especially if you’re just getting started with PrizmDoc Viewer.
But, of course, using an Accusoft-hosted backend may not work for your business. Maybe you are not allowed to ever let documents leave your network, even temporarily. If that’s the case, you’ll need to host and manage the backend yourself. As customers start looking into what it takes to do that, we get a lot of questions about how load balancing works. How is the compute workload spread across the servers? How are HTTP requests routed to the the correct machines? What sort of load balancer(s) should I be using? Those are the kinds of questions we’ll cover in this post.
To do that, though, we first need a more detailed picture of the backend. For more on PrizmDoc load balancing, check out the rest of my article here.

Adam Cooper, Software Architect, PrizmDoc
Adam joined Accusoft in 2010 and works as a software architect for the PrizmDoc family of products. He focuses primarily on API design, customer experience, and internal tooling to support product development. Prior to Accusoft, Adam developed software for a variety of organizations, mostly focusing on .NET, web development, and automated testing. Outside of work, Adam enjoys photography, music composition and engraving, discussing the Bible, and spending time with his family and church.

Ever feel like there aren’t enough hours in the day? Here’s a scenario which will undoubtedly resonate with you if you are like several of our clients. You’re a senior app developer for a provider of data management solutions for the insurance industry.
There are two weeks left before you head off for vacation. Your team is working on UI and code fixes which arose out of UAT on your company’s latest major upgrade cycle. Everything was wrapping up nicely, until the product manager (PM) approached your desk with a peace offering of a double shot latte and a Philly cheesesteak sandwich.
You quickly discover that the peace offering is due to the fact that the upgrade was supposed to include a document and file management functionality, but it had been left off the project EPIC.
The PM hands you a list of functional specs, including a mobile-friendly document viewer, markup, document capture, image compression, eSignature functionality, and PDF OCR for document discoverability.
She has that “deer in the headlights” look as if you are about to go to Defcon 5. Instead, you smile, thank her for breakfast, and gather the troops for a quick scrum. Your application was built for extensibility requirements like this, and RESTful APIs are your jam.
You and your team don’t have to write the base code to meet these requirements. You and your colleagues just have to buy the API licenses, download some code, access some cloud-based functionality, and work your magic on the APIs to wrap it into your platform.
Why Labor with Lumber When You Build with Lego?
Even if you had these requirements out of the gate, you probably would have sought out some APIs to help you build, right?
At the end of the day, the goal is to increase information worker productivity and effectiveness within your client base and delivering the kind of value which ensures lasting relationships. You never want to reinvent the wheel and add more project scope than necessary.
Should your team rush to build custom functionality into their native application, and risk non-compliance with regulatory standards like HIPAA, ISO 27001 or SOC 2 or 3?
Not likely, especially when there are probably additional requirements for viewing and marking up raster and vector files. There might even be extra requirements for integration with SharePoint or CRMs.
Buying vs. Building Applications
API code can always be skinned with a custom user interface to provide a seamless user experience. Developers shouldn’t be discouraged from hacking the development process by leveraging existing code to accelerate deployments.
It’s the premise platforms like GitHub were built on. Instead of months of development work, an API/SDK package can exponentially accelerate time to market. If an application development team has adopted DevOps or Agile methods, strategies to ensure continuous development and continuous integration are key.
An article in CIOReview.com says it best: “By using APIs, you extend the capability of your development team. The key is to ensure the vendor, application, and the APIs all exceed your expectations.”
ImageGear and PrizmDoc
Organizations in regulated industries like government, healthcare, and financial services create, manipulate, and store a lot of electronic and physical documents. They often need functionalities like viewing, converting, and redacting that help them stay productive but also compliant.
The combined API packages support more file types, compress files for faster loading, and offer customers a mature, secure, and proven document viewer for sensitive files. Healthcare facilities often have devices which don’t have the capacity to manage native document viewers, so browser-based viewers offer better viewing and editing capability.
Documents are often scanned in large batches and require post-capture enhancement, such as despeckling, deskewing, and OCR to enable keyword/phrase searching within individual files and images. Need to enable your customers to remain within your application, yet complete multiple tasks? Why not enable some functionalities like:
- Converting multiple file formats into one document
- Building and capturing forms
- Watermarking
- Signing a document without importing another third-party service
- Gaining quality control on a scanned image
- Comparing two similar documents such as contracts by redlining them for legal review
Building all of this functionality is a lot of heavy lifting. Our APIs are mature, QA-vetted, and ready to integrate with apps which are coded in C, C++, Java, or .NET.
For those applications which already use PrizmDoc or ImageGear, integrating the other API into production alongside it is a seamless process. Those developers who have worked with your support team will be familiar with getting any assistance they may require.
Start with Core APIs and Extend as Business Evolves
In fact, when PrizmDoc Viewer and ImageGear work together, they provide the ability to recognize more file types, search within PDFs and images, create new documents from different file types, and reorganize content to create a brand new document.
Especially useful for businesses that process a variety of different file types, these SDK and API integrations revamp your application, making your application’s end-users more productive and efficient.
Ready to enhance your document and imaging functionality in your applications, without complex coding? Create an Accusoft account, or use your login to get started.

Technology is simplifying communication between humans and computers. The old keyboard-and-mouse model has become antiquated for many uses, and even touch screens introduce inefficiencies to the process of entering and retrieving information. As multitasking has become the norm in both personal and professional life, a very pure simplicity – voice technology – is emerging as the new standard for managing devices in the home as well as the office.
The use of voice commands is a simple, natural way to control machines, freeing up the user’s hands much like speakerphones, headsets and the popular Amazon Echo and Google Home smart speakers. Word recognition technology still isn’t perfect and can lead to some unintended (and very funny) gaps in semantics, but most users are more than willing to accept the occasional misstep in exchange for the convenience of breaking away from the keyboard and screen while operating a device.
Who can voice technology help?
There are numerous examples of cases where this technology is useful, such as in presenting information. Years ago, a slide show presenter might use an assistant to manually advance through a display, typically, sequence of images or data. More recently, a Bluetooth controller with “Next” and “Previous” buttons could maneuver somewhat more smoothly through the slides. But voice commands take the interface to another level, freeing the presenter to interact more freely with the audience and possibly present more information in parallel.
Users reading instructions to perform a complex task can also benefit from the technology. Voice commands controlling a phone or tablet can help navigate through a PDF or Microsoft Word document detailing recipes, furniture assembly or even engine repair while leaving the operator’s hands – and eyes – free to handle the job.
Portability is another key element in the use of voice commands. The ability to verbally control an application makes it much more accessible and convenient on the go, whether at a hospital, school or other public place where typing can be awkward and time-consuming. Retrieving maps, directions and contact information are all important tasks for mobile users that are simplified by voice functionality.
An entire generation, of course, is already accustomed to this technology, using it to handle everyday tasks without a second thought: “Siri, where’s the nearest coffee shop?” “Alexa, play that song that goes ‘Make a change, and break away.’” More and more devices facilitate the exchange of information by handling voice commands just like these, indulging the growing demand for automation.
Making the PrizmDoc viewer understand voice
We identified a number of use cases where voice support can be a huge help for anyone viewing information. The versatile PrizmDoc is a powerful tool for accessing a multitude of documents and images, and here we will detail the technical process of making it understand voice commands.
PrizmDoc allows multiple types of customization, and adding basic voice control is not too different from adding a custom button. For our purposes we are using Web Speech API to process voice data.
We will add a button which starts voice recognition in the viewer. When the button is pressed, the viewer will listen and process a few voice commands, such as scrolling, page navigation and adding annotations.
If the viewer cannot understand a command, it will indicate this with a red question mark in the voice recognition button.
Adding the button HTML
The bulk of the viewer markup is inside the file viewerTemplate.html; this includes all the toolbars and vertical slide-outs.

OS and browser requirements
This example was tested in the Chrome browser running Windows. See the “Browser Compatibility” section on Mozilla’s developer site for more details on browser support.
A more complete viewer solution
PrizmDoc, compatible with all programming languages and platforms and able to display all major file formats, has established itself as the premier development toolkit for document and image viewing. Adding voice support to its user interface makes it easier to operate just as it saves time and trouble for developers and end users alike.
To learn more about PrizmDoc and its various uses in virtually unlimited industries, click here. To view demos of PrimzDoc’s features, click here. To contact Accusoft with any questions or comments about this blog or its products for document and imaging solutions, click here.
Written by: Cody Owens

-
- How quickly can your team take a code base, package it, test it, and put it into the hands of your customers?
-
- Can you push a button to automagically make it happen?
- And, once your customers have your product, can you be confident that it will work for them out of the box?
We at the Accusoft PrizmDoc group asked ourselves those questions in 2016 and discovered a wide array of opportunities to improve how we deliver our product.
Here we share how we reduced our feedback cycle from three months to three days, enabling rapid delivery of beta PrizmDoc builds and confident, seamless delivery of release builds.
What is Continuous Delivery?
Continuous Delivery, the movement toward rapid working releases, focuses our efforts on knowing as quickly as possible when to release a change to customers. Whereas Continuous Integration focuses on taking code and packaging it, Continuous Delivery goes a step further by identifying what to do with that package before release.

A common assumption is that when code works in one environment, it should work in others. But through the lens of Continuous Delivery, we have to assume our product is guilty until proven innocent. And how do we prove its innocence? Automated testing in production-like environments. In this way, we can be confident that at release time our product won’t explode on takeoff.

Moving from testing on a small, dedicated environment to a many production-like environments can be complex. But implementing a Continuous Delivery release workflow is well worth the effort. The product will be deployable throughout its lifecycle. Everyone – not just the development team – can get automated feedback on production readiness at any time. Any version of the product can deploy to any environment on demand. And in our case, beta builds can release to customers for early feedback on bug fixes and new features. Together, we realized that these benefits far outweigh the cost of putting up with release pain year after year.
Evaluating Our Starting Point
Like most modern software teams, we believe in the value of test-driven development. We already had many thousands of unit, contract, and integration tests verifying the ability of our products to solve business needs. So, we could be confident that the product could run on some specific environment with some specific configuration. But there were a few key problems we had to address:
- Spawning many production-like environments was uneconomical
- We could not automatically test the GUI of our product
- There were no explicit, automated performance tests against business-valued behaviors
Testing On Realistic Environments
We tackled the expense of production-like environments first. At the time, we were using Amazon Web Services EC2 instances for build agents that could test and package code. On each code change, new instances launched to run tests. While these instances were fast, reliable and cloud-based, they were uneconomical. And because spending gobs of money is effortless when spawning instances for testing or development, access was guarded. Reevaluating our needs, we realized that scalability or flexibility of the cloud wasn’t necessary for testing purposes. We knew we needed to shut off the cloud-hosted cash vacuum – but what was our alternative?
Hybrid cloud is becoming attractive as a best-of-both-worlds solution to cloud-hosting needs. Perhaps a more accurate term is “local cloud hosting” – on-prem value but with most of the features offered by the “real” cloud. To this end, we turned to OpenStack as our EC2 replacement for development builds. With OpenStack, we can still spin up instances, store VM images and snapshots, create load balancers and more without the cost associated with the cloud. A single investment in the local hardware was comparable in cost to one additional year of cloud usage. If it didn’t turn out so well, we could just switch back a year later.
After flipping the switch, we transferred our build agents to OpenStack’s hybrid cloud. Before, some tests took many hours and could only run once per day or even once per week. But with the reduction in testing costs, we now run the dailies at every commit and the weeklies every day. This difference in feedback time is monumental; developers can be confident that their new code won’t fail automated tests a week later after the user story has closed.
As we increased our hybrid cloud test agent workload, we ran into a unique problem. As opposed to running instances in the “real” cloud, we now have to deal with hardware limitations. We have a specific number of physical CPUs available. We have a specific amount of memory to use. This forced us to rethink what tests we ran and how we ran them.

Failing Fast, Failing Cheap
To optimize our resource usage, we need bad commits or configuration changes to fail fast and early. When one stage fails, the next stage(s) shouldn’t run because that build isn’t releasable. We needed a way to schedule, chain and gate test suites.

Enter Jenkins. Jenkins is a flexible build system that enables a simple pipeline-as-code setup for all sorts of purposes. In our case, we opt to use it as the platform that pulls the built product installer, installs it and runs batteries of progressively stringent tests against it. A stage can run tests against multiple nodes. We created production-like nodes that launch from our hybrid cloud and use the built-in gating functionality in Jenkins. Subsequent test stages don’t run following a test failure. Since pipelines are version controlled, we always know exactly what changes affect a given run.

Testing Like A User
By this point, our tests can run inexpensively and easily across production-like environments. This enabled us to rethink what tests we were running and build upon our coverage. At release time, we spent a sprint across two teams just to test deploying the product and pushing buttons to verify the GUI worked. The plain English test instructions were subject to interpretation by the tester, leading to nondeterministic results from release to release. This cumbersome effort was necessary to test the GUI sitting on top of our core API product.
While this manual testing process uncovered bugs nearly every release, it was unthinkable in terms of ROI per man-hour. The late feedback cycle made product GUI changes stressful. A developer might not know that the GUI component they just added is unusable on an Android device running Firefox until the release testing phase three months later. Finding bugs at release time is dangerous, as not all bugs are always resolved before the release deadline. Regressions and bugs might make their way into the product if they’re not severe, or they might postpone delivery of the product altogether.
Automating these types of manual tests improves morale, reduces feedback time and asserts that the GUI either passes or fails tests in a deterministic way. Furthermore, it opens a route to Behavior Driven Development language that centers around business-valued behaviors on the front end of the product. For instance, we use the Gherkin domain-specific language to author tests in plain English that are parseable by a testing code base into real executed test code. Non-technical members of the team can author plain English “Given [state of the product], When I [do a thing], Then [a result occurs]” feature descriptions that map 1:1 to test code.

Today, all major browsers have automation REST APIs to enable driving them in a native non-JavaScript way without a real user. To eliminate the hassle of changing test code between browsers or authoring reliable tools to talk to those automation APIs, we use Selenium WebDriver. WebDriver is available in many popular languages including Java, Python, Ruby, C#, JavaScript, Perl and PHP.
From BDD test code, we execute end-user tests with WebDriver to verify real usage of the product. Because the WebDriver APIs enable “real” user events and not JavaScript event simulations, we can be confident that mouse, touch and keyboard actions actually do what we expect across a range of platforms. On test failures, we take a screenshot and save network traffic logs from the browser to trace the failure back to a front end or microservice source. Some test authors even automatically save a video of the last X seconds leading up to the failure to investigate unexpected, hard-to-reproduce behavior.

Altogether, these new front-end tests enable us to supplant the rote work of fiddling with the product across different browsers and devices for each release. They give us rapid feedback for every commit that the product has not broken for a front-end user. Before, we couldn’t know until release testing. Development confidence goes way up and agility improves as we can guarantee that we won’t have to interrupt the next sprint to fix an issue introduced by new code.
The Value Of Manual Tests
This is not to say that manual testing should be supplanted by automated testing. Exploratory testing is necessary to cover complicated scenarios, unusual user behaviors and platforms that automated tests don’t cover. Not everything is worth the time investment of automating. Bugs found during exploratory tests can be fixed and later covered by automated tests.
Your product’s test coverage should look like a pyramid where unit test coverage is thorough, integration tests are somewhere in the middle, and product-level end user tests are broad but not deep.

As expensive as manual testing can be, authoring and maintaining end-user tests can be expensive if done poorly. Changes to the front-end of the product can break all the GUI tests, though using the Page Object design pattern can mitigate this. Browser updates can also break end-user tests. Poor product performance can lead to unexpected behavior, resulting in failed tests. And not all browser platforms support all parts of the WebDriver spec, resulting in edge cases where JavaScript does need to be run on the page on that platform to fill in the gap.
Keep end-user tests broad and don’t use them as a replacement for in-depth, maintainable integration and unit tests. If a feature is testable at the unit or integration level, test it there!
On the PrizmDoc team, we’ve freed up weeks of regression testing time at release through adding these end-user automation tests. After cursory end-user regression tests, we host a fun exploratory Bug Hunt with prizes and awards.
Who can find the most obscure bug? The worst performance bug? Who can find the most bugs using the product on an iPad? Your team can gear testing efforts towards whatever components are most important to your customers and raise the bar on quality across the board.
Automating Nonfunctional Tests
Performance and security, among other nonfunctional requirements, can be just as important to our customers as the features they’ve requested. Let’s imagine our product is a car. We know that the built car has all the parts required during assembly. We also know that the car can start up, drive, slow down, turn and more.
But we don’t know how fast it can go. Would you buy a car that can only go 20 MPH? What if the car didn’t have door locks? These concerns apply similarly to our software products.
The next step, then, is to automate tests for nonfunctional requirements. Even one bad commit or configuration change can make the product unacceptably slow or vulnerable. So far, we have added automated performance tests using Multi-Mechanize. Many similar tools can accomplish this task so there’s no need to dive into details, but the key point is configurability.
Our customers don’t all use the same hardware, so it doesn’t make sense to test on every possible environment. Instead, we focus on measuring performance over time in a subset of production-like environments. If performance goes below a particular threshold, the test fails. With configurability in mind, if a customer is evaluating whether to use PrizmDoc, we can simply deploy to a similar environment (CPUs, memory, OS type, license, etc) and gather metrics that will allow them to easily plan capacity and costs, which can often seal the deal.
And since performance tests run on every successful change, we can gauge the impact of optimizations. For example, we found that a microservice handled only two concurrent requests at a time. The fix? A one-line change to a configuration parameter. Without regular performance tests, gathering comparative performance and stability would be difficult. With regular performance tests, however, we were confident in the value of the change.

Real Impact
Continuous Delivery has improved every aspect of the PrizmDoc release cycle. Customers praise our rapid turnaround time for hotfixes or beta build requests. We now thoroughly measure the delivery value of each commit. End-user tests verify the GUI and performance tests cover our nonfunctional requirements. The built product automatically deploys to a range of affordable production-like environments. Any member of the product team can get release readiness feedback of the current version at a glance. Instead of a three month feedback cycle, developers see comprehensive test results against their changes within a day. The difference in morale has been tremendous.
If your organization is not quite there yet, we challenge you to start the Continuous Delivery conversation with your team. Hopefully our experience has shed light on opportunities for your product to make the jump. You might get there faster than you expect.
About the author
Cody Owens is a software engineer based in Tampa, Florida and contributor to continuous deployment efforts on Accusoft’s PrizmDoc team. Prior to his involvement with document management solutions at Accusoft, he has worked in the fields of architectural visualization and digital news publishing. Cody is also an AWS Certified Solutions Architect.

Full-featured document viewer outperforms open source alternative
There are various HTML5 document viewers available for embedding in web and mobile applications. Typically, developers have a few minimum requirements for a viewer: it must display PDFs and Microsoft Office documents, should embed easily into their front-end HTML/CSS/Javascript. Sometimes additional features are needed, such as additional file support, signature, annotation, or redaction.
ViewerJS is an open source product powered by PDF.js, a viewer created by Mozilla for its Firefox browser. ViewerJS appeals to developers due to its cost (zero), its ease of integration and the simplicity of its embedded viewer. It’s written in JavaScript and can display PDF and ODF (Open Document Format) files, but it doesn’t support Microsoft Office documents. This means it doesn’t display basic files like Word documents (.doc) and Excel spreadsheets (.xls). This limitation means many projects will need to evaluate alternatives.
Complete Functionality – More Than Just Document Viewing
PrizmDoc is a far more powerful alternative, offering a number of features unavailable in ViewerJS. PrizmDoc handles over 50 different file formats, including Microsoft Office documents, CAD files, PDFs and major image types. It also offers:
- Search: Find a text string and see all instances of the text in the document for easy reference.
- Annotation: For collaborative work on documents, this allows users to highlight areas of a document, inserting comments or instructions or emphasizing key passages.
- Redaction: Cover sensitive information in the displayed files – a key consideration for government, legal and financial institutions.
- eSignature: This enables readers to sign documents, agreeing to their terms.
Compare PrizmDoc and ViewerJS
PrizmDoc goes far beyond open source options in providing a comprehensive alternative for embedded document viewing for applications:
PrizmDoc: Fully Supported & Dependable For The Long Haul
Accusoft offers complete support with PrizmDoc, with our engineers always ready to assist with implementation and integration. And PrizmDoc is always being improved, with new versions released regularly to make the most of new innovations. ViewerJS offers none of these advantages.
View this complete set of product demos to try out PrizmDoc, or contact us here with any questions you might have. And use the trial download link below to test PrizmDoc out in your own applications.

Are you looking to add an HTML5 document viewer to your web or mobile application, but are unsure of the costs involved? Here’s how to calculate the cost vs. benefits of a web-based document viewer for your organization.
How An HTML5 Viewer Can Save Your Organization Time & Money
A lot of employee time gets wasted everyday viewing, sending, and looking for documents. For example, one study found that a typical lawyer spends 4.3 hours per week searching for documents and recreating lost documents.
Adding an HTML5 document viewer can actually save your organization money by saving employees time and hassle:
- Documents stay in a central repository, making it nearly impossible to lose documents. (A PricewaterhouseCoopers study estimates that every lost document costs the company $122 to find.)
- No need to download and install viewers on desktop or mobile devices.
- No time spent emailing documents back and forth.
- Save time with automatic version management and reconciliation.
Estimating The Cost Savings Of An HTML5 Document Viewer
Here’s a simple formula to estimate how adding an HTML5 document viewer to your company’s document system(s) could impact your organization’s bottom line:
x
x
x
Studies show employees spend 10% or more of their time on document related issues. But let’s be conservative – even if a web-based viewer only saves 10 minutes per day per employee, this adds up to substantial savings over a year’s time.
For example, in an organization with 100 people:
x
x
x

We’ve received some questions from customers recently about PrizmDoc Application Services, such as:
- What is PrizmDoc Application Services (PAS)?
- Why do I need it?
- How does it benefit me?
- I’m interested in PrizmDoc Cloud hosted, why do I need to install PAS?
- Where do I install it?
To provide some further clarity, we’re going to answer these questions for you today.
What is PAS?
So, just what is PAS? PAS is a service that provides application-level logic for the viewer; such as enabling document viewing sessions through the PrizmDoc Server, saving and loading of markup, and handling opening of documents.
Why would you need PAS?
This service is the gateway between the Viewing Client and PrizmDoc Server. It handles document and markup storage as well as forwarding requests to PrizmDoc Server.
How does PAS benefit you?
PAS reduces the size of the Client package. This makes for a much simpler process for installing the Client, which allows you to get the product up and running much quicker than before. An additional benefit is that the developer no longer needs to understand or edit additional code that was previously in the client. This code now resides in PAS.
Why do PrizmDoc Cloud-Hosted customers need to install PAS? Don’t they just need the Client?
The Client by itself does not have the capability to request viewing services such as content conversion, or markup services such as annotation, redaction, pre-conversion, and search. These service requests are handled by PAS.
Where do I install PAS?
PAS is intended to run on the same server as your web tier/application, although that’s not required. Because it’s a standalone service, it can run anywhere between your web tier/application and PrizmDoc Server, including on its own separate machine if necessary.
Understanding the Architecture Using PrizmDoc Application Services
The Web Tier Samples in PrizmDoc include a small amount of proxy code that forwards viewer requests to PAS. This is added for an enhanced out-of-box experience when evaluating, and we recommend using a reverse proxy in production for optimal performance. Instructions on how to configure a reverse proxy can be found in the “Configuring PrizmDoc Application Services in your Server’s Entry Point” topic.

In this architecture, PAS handles the business logic of running the Viewing Client, while providing a flexible API to allow handling only specific calls with custom application logic while letting the rest be handled by the service. Since this is a standalone HTTP service, it does not necessarily need to run on the same machine as the Web Tier anymore. It can also run alongside PrizmDoc Server, or on its own separate machine.
The minimal code that comes with the Web Tier Samples is now truly a suggestion, as any proxy into PAS will accomplish the task. For a more performant solution, we would encourage you to handle proxying through your web server of choice (such as Apache, NGINX, or IIS), allowing your web application to only contain your own logic, without the need to integrate any Accusoft sample code. This is outlined by the architecture below:

For more information about PrizmDoc Application Services please reference the PrizmDoc documentation.
Document management security is essential for keeping company information private and secure. However, not all businesses maintain an ongoing document management process with their employees.
According to LBMC Technology Solutions, “Efficient document management involves having a well-written, strong, and clear policy as well as a computer system (or in some cases several systems) that can index information for easy retrieval and allow for varying levels of security in accessing the documents.”
Recent research from ComputerWorld shows that the average organization shares documents with 826 external domains, which include corporate business partners and personal email addresses. It’s obvious that with so much information shared internally and externally, document security is a huge risk for businesses of any size.
Accusoft’s recent survey of 100 IT managers and 250 full-time employees from the U.S. showed interesting results, represented in the infographic below.

Given these statistics, it’s important to evaluate your own document management security policies to ensure privacy for your data and your company.
Get the Full Report — FREE
For more information on document awareness gaps, please download our full data study, Closing the Document Management Awareness Gap, which includes many more insights on document security.

Native rendering is essential in several industries. When it comes to sharing documents, the variety of applications needed to view each file can be overwhelming. Companies that use an advanced document viewing tool have the capability to share files with ease, switching between formats like Word, Excel, and PowerPoint effortlessly.
However, near-native rendering can often prohibit the viewer from grasping the whole picture. Companies looking for a way to enhance their document sharing capabilities, while converting Microsoft Office (MSO) products natively, now have an easier solution.
Near-Native vs. Native Rendering
First off, let’s explain the difference between near-native and native rendering.
With a near-native render, the document viewer is creating an interpretation of the original document. However, the final product is often altered. Near-native rendering is best used in circumstances when the original, unaltered document does not change its influence even if gently modified.

Near-Native Rendering (left) vs Native Rendering (right)
Native rendering is the presentation of the file in its original format. It provides a clearer, more accurate depiction of the information. This process is essential for industries using specific tactics that require a perfect representation of the original document, such as eDiscovery in legal.
MSO Conversion Feature Now Available
Accusoft released the latest version of PrizmDoc on November 8, 2016. With PrizmDoc v12.0, users can add on the Microsoft Office Conversion feature that enables native rendering in all MSO formats.
Companies that typically render Word, Excel, and PowerPoint files can now use this feature to capture a native render in PrizmDoc’s HTML5 viewer. If the file is not a Word, Excel, or PowerPoint document, PrizmDoc will render the file as near-native. This type of conversion creates objects for each piece of text and coordinates how each object lines up on a page, which results in a near-native SVG.
However, the all-new MSO feature creates an SVG that replicates the original document in native format. PrizmDoc automatically starts Microsoft Office in the background when a file is rendered. The program can support as many instances of Microsoft Office as there are CPU cores in the server. MSO processes multiple instances of MSO at the same time, allowing a faster and more user-friendly experience.
The Benefits of Native Rendering and MSO Conversion
Presented as a self-hosted add-on to the current PrizmDoc product, MSO conversion is essential for a variety of industries that rely on native rendering to present accurate document depictions.
Don’t worry about fidelity issues with MSO documents. Convert them with ease using PrizmDoc 12.0’s new feature. Built to accommodate the more precise audience, this new add-on saves companies time and money. Take advantage of native rendering and relinquish any frustration of near-native complications.
New and Improved PrizmDoc v12.0
While MSO conversion is just one of a few new features in PrizmDoc v12.0, the enhancements to this offering are influential for companies that need precise document clarity. Currently, users who complete conversions through near-native rendering are receiving an interpretation of the original document. With MSO, the files convert seamlessly to emulate the original.
Since near-native rendering is not always compliant with a company’s document viewing requirements, MSO conversion is a valuable alternative. Ready to download? We’ve got you covered.
If you have any further questions about purchasing or upgrading, don’t hesitate to contact us. For more information on installation, visit our website for documentation.