Technical FAQs for "SmartZone"

Ongoing Legal Digital Transformation
There are many challenges facing the legal industry that legal tech and new emerging legal technology can help solve, but getting firms to adopt new technology to address these challenges can be a hurdle. But the most recent challenge within the eDiscovery process is compounding them all.
The Arrival of New eDiscovery Challenges
The change to a remote/hybrid work environment starting in 2020 during the worldwide COVID pandemic transformed the working world. Even while some companies have returned to the physical workspace, hybrid and fully remote working conditions continue to exist. This means that the collaborative working social platforms and mobile apps we all used to communicate and work with (Teams, Slack, Zoom, Webex, WhatsApp, Google Meet, etc.) are here to stay.
Regardless of whether employees are in-office, hybrid, or working remotely, using these collaborative working social platforms has become the new norm. This has had profound effects on legal firms performing eDiscovery, most of whom still depend on tools and review processes designed for standard digital documents (such as .doc, .xlxs, .ppt, etc), paper documents, and email. The process of collecting, viewing, searching, redacting, and collaborating across traditional documents and emails has pivoted, and firms are responsible for including the digitized content from these collaborative working social platforms in their eDiscovery.
Compounding the Problem
Processing this new collaborative working social content is a big enough challenge on its own. Unfortunately, many in the legal industry weren’t fully optimized with their digital transformation by adopting previously available legal tech. While some traditional eDiscovery tools have reached maturity and are being utilized by firms, many slower-to-adopt firms are still fighting internally to have legal tech implemented.
How can firms (both early adopters and those still in the digital transformation process) prepare for eDiscovery across these new platforms filled with chat streams, emojis, and video recordings?
Enter Third-Party Software Integrations
Legal tech independent software vendors (ISVs) can be assured that there is technology available that can support their eDiscovery across these collaborative working social platforms. But better still, they don’t need to build a solution from scratch.
Readily available and easy to adopt, third-party software integrations allow ISVs to add the capabilities they need without disrupting development timelines or building features from scratch. The ability to view, search, annotate, and redact content within documents securely inside an existing application without sacrificing everyday functionality is powerful.
Take on Your eDiscovery Challenges with Accusoft
Accusoft software integrations help legal tech ISVs build a more productive process for case review and eDiscovery. With unique technology that enables easy digital document processing, manual processes like search and redaction are no longer labor-intensive. Accusoft’s digital document lifecycle technologies streamline collaboration and information-sharing while keeping files secure and original metadata intact.
Looking specifically to address the new challenges of processing new collaborative working platform content within your eDiscovery process? Accusoft’s solutions can not only view these new collaborative platform transcript file types (including JSON, VTT, DOCX) but also search, redact, and offer secure collaboration directly inside your application.
To learn more about how Accusoft integrations can support your legal digital transformation and eDiscovery challenges, talk to one of our technology experts today.
_ _ _
For more information on Accusoft’s software integrations for eDiscovery, case, and practice management applications, visit our Legal industries page.
Continuous innovation has allowed Accusoft to build sustained success over the course of three decades. Much of that innovation comes from talented developers creating novel solutions to everyday problems, many of which go on to become patented technologies that provide the company with an edge over competitors.
Others, however, are the byproduct of looking at problems from a different perspective or using existing technologies in unique ways. Accusoft supports both approaches by hosting special “hackathon” events each year. These events encourage developers to spend time working on their own unique projects or try out ideas they think may have potential but have never been implemented.
For this year’s hackathon, I took a closer look at how our SmartZone SDK could be implemented as part of an automation solution within a .NET environment without creating an entire application from the ground up. What I discovered was that PowerShell modules offer a quick and easy way to deploy character recognition for limited, unique use cases.
.NET and PowerShell
One of the underestimated abilities of the .NET infrastructure is support loading and executing assemblies out of box from the command line using a shell module. Although there are many shell variants available, PowerShell comes preinstalled on most Windows machines and is the only tool required to make the scripts and keep them running. PowerShell also runs on Linux and macOS, which makes it a true cross-platform task automation solution for inventive developers who crave flexibility in their scripting tools.
Incorporating the best features of other popular shells, PowerShell consists of a command-line shell, a scripting language, and a configuration management framework. One of the unique features of PowerShell, however, is that unlike most shells which can only accept and return text, it can do the same with .NET objects. This means PowerShell modules can be used to build, test, and deploy solutions as well as manage any technology as part of an extensible automation platform.
Implementing SmartZone Character Recognition
Accusoft’s SmartZone technology allows developers to incorporate advanced zonal character recognition to capture both machine-printed and hand-printed data from document fields. It also supports full page optical character recognition (OCR) and allows developers to set confidence values to determine when manual review of recognition results are necessary.
Implementing those features into an application through a third-party integration is the best way to incorporate recognition capabilities, but there are some use cases where they might need to be used for general tasks outside of a conventional workflow. A number of Accusoft customers, for instance, had inquired about simple ways to use some of SmartZone’s features in their existing process automation software without having to spend weeks of development time integrating those capabilities on a larger scale.
Thanks to the versatility of PowerShell, there’s no reason to build such an application from scratch. SmartZone’s zonal recognition technology can easily be incorporated into any .NET environment with just a few snippets of code. PowerShell syntax itself is not very difficult to understand and for a quick start it should be enough to use a Windows Notepad application, but we recommend using your favorite integrated development environment (IDE) for a better experience.
Getting Started
First, you need to download SmartZoneV7.0DotNet-AnyCPU.zip from the Accusoft SmartZone download page and unpack it to any suitable directory. This bundle contains all required binaries to run SmartZone.
Create a Simple.ps1 file inside the unpacked directory and start typing your script:
using namespace System.Drawing
using namespace System.Reflection
using namespace Accusoft.SmartZoneOCRSdk
# Load assemblies.
Add-Type -AssemblyName System.Drawing
$szPath = Resolve-Path ".\bin\netstandard2.0\Accusoft.SmartZoneOCR.Net.dll"
[Assembly]::LoadFrom($szPath)
# Create a SmartZone instance.
$szObj = [SmartZoneOCR]::new()
$szAssetsPath = Resolve-Path ".\bin\assets"
$szObj.OCRDataPath = $szAssetsPath.Path
# Licensing
# $szObj.Licensing.SetSolutionName("Contact Accusoft for getting the license.")
# $szObj.Licensing.SetSolutionKey(+1, 800, 875, 7009)
# $szObj.Licensing.SetOEMLicenseKey("https://www.accusoft.com/company/legal/licensing/");
# Load test image.
$bitmapPath = Resolve-Path ".\demos\images\OCR\MultiLine.bmp"
[Bitmap] $bitmap = [Image]::FromFile($bitmapPath.Path)
# Recognize the image and print the result.
$result = $szObj.Reader.AnalyzeField([Bitmap] $bitmap);
Write-Host $result.Text
# Free the resources.
$bitmap.Dispose();
$szObj.Dispose();
This simple code snippet allows you to use SmartZone together with PowerShell in task automation processes like recognizing screenshots, email attachments, and images downloaded by the web browser. It can also be deployed in other similar cases where the advantages of PowerShell modules and cmdlets can help to achieve results faster than writing an application from scratch.
Another Hackathon Success
Identifying a new way to deploy existing Accusoft solutions is one of the reasons why the hackathon event was first created. This script may not reinvent the wheel, but it will help developers save time and money in a lot of situations, which means fewer missed deadlines and faster time to market for software products. Developing unique approaches to existing problems can be difficult with deadlines and coding demands hanging over a developer’s head, so Accusoft’s hackathons are incredibly important for helping the company stay at the forefront of innovation.
To learn more about how that innovation can help your team implement powerful new features into your applications, talk to one of our solutions experts today!

Today’s customers expect more of software applications than ever before. Piecemeal solutions that provide only a few noteworthy features are quickly being overtaken by more comprehensive platforms that deliver an end-to-end experience for users. This has prompted developers to incorporate more capabilities, while also building innovative features that set their solutions apart from the competition. Thanks to third-party software integrations, they’re able to meet both demands.
What is Third-Party Software Integration?
Third-party software integrations typically come in the form of SDKs or APIs that provide applications with specialized capabilities. Rather than building complex features like optical character recognition (OCR), PDF features, or image cleanup from scratch, developers can instead incorporate the necessary features directly into their software via an SDK or use an API call to access capabilities without expanding their application’s footprint.
From a user experience standpoint, third-party software integrations allow developers to build more cohesive software solutions that provide all the essential features a customer may require. Instead of pushing them into a separate application to interact with documents, provide a signature, or fill out a digital form, they can instead deliver an unbroken experience that’s easier to navigate and manage from start to finish.
4 Key Third-Party Software Benefits
There are a number of important benefits organizations can gain from using third-party software integrations, but four stand out in particular:
1. Reduce Development Costs
When evaluating whether it makes sense to build functionality for an application in-house or buy a third-party software integration, cost is frequently one of the key considerations. There is often a tendency to think that it would be more cost-effective to have developers already working on the project simply build the capabilities they need on their own. After all, there’s no shortage of open-source SDKs and other tools that are available without having to pay licensing or product fees.
In practice, however, this approach usually ends up being more expensive in the long run. That’s because the developers working on the project often lack the experience needed to build those capabilities quickly. A software engineer hired to help build AI software, for instance, probably doesn’t know a lot about file conversion or annotation. While they might be able to find an open-source tool to build those features, they still need to do quite a bit of development work and on-the-job learning to get the new capabilities stood up and thoroughly tested.
Focusing on these features means they’re not focusing on the more innovative aspects of their application. From a cost standpoint, that means they’re being paid to build something that’s already readily available in the market. When these internal development costs are taken into account, it’s almost always more cost effective to buy ready-to-implement software features built by an experienced third party. As the saying goes, there’s no reason to reinvent the wheel.
2. Get to Market Faster
Software developers are always working against the clock. With new applications hitting the market faster than ever, there’s tremendous pressure to keep development timelines on track and avoid missing important deadlines. This helps projects stay within their expected budgets and prevents potential competitors from getting to market faster. Any steps that can be taken to accelerate development and potentially shorten the timeline to releasing a product could mean the difference between becoming an industry innovator or being labeled as an also-ran.
Third-party software integrations allow developers to quickly and seamlessly integrate essential capabilities into applications without compromising their project timeline. Rather than building features like forms processing, document annotation, and image conversion from scratch, teams can instead use third-party SDKs and APIs to add proven, reliable, and secure features in a fraction of the time. By keeping projects on or ahead of schedule, they can focus on delivering a better, more robust product that exceeds customer expectations.
3. Expand Application Features & Functionality
Software development teams typically possess the experience and expertise needed to build the core architecture and innovative features of a new application. In many cases, they’re designing something novel that will provide a point of differentiation in the market. The more time they can spend on refining and expanding those capabilities, the more likely the application is to make an impact and win over customers.
What these developers often lack, however, are the skills needed to implement a variety of other features that will enhance the application’s functionality. Features like document conversion, OCR, PDF support, digital forms, eSignature, and image compression are complex and difficult to build from scratch. By integrating third-party software, developers can leverage proven, feature-rich technology to expand their application’s capabilities. This not only allows them to improve their solution’s versatility but also enhance the overall user experience by eliminating the need for external programs or troublesome plug-ins.
4. Access Specialized Engineering Support
Incorporating features like PDF support, image conversion, and document redaction into an application poses several challenges. Some of those challenges don’t show up right away, instead, they become evident long after a software product launches. If the developers don’t have a lot of experience with the technology behind those features, minor issues can quickly escalate into serious problems that leave customers unhappy and willing to look elsewhere for alternatives. No organization wants to be caught in a situation where a bug embedded in an open-source tool renders a client’s valuable assets unusable.
By leveraging proven, tested, and secure third-party software integrations, developers gain access to support from experienced engineering teams with deep knowledge of their solutions. In addition to documentation and code samples, they can also speak directly with developers who can provide guidance on how to best integrate features and resolve issues when they emerge. The best integration providers will even work with organizations to customize their solutions to meet specific application needs, which helps create even smoother user experiences and enhances reliability.
Integrating Third-Party Software with Accusoft
For over 30 years, Accusoft has helped organizations add essential features like barcode recognition, file conversion, document assembly, and image compression to their applications through an innovative line of SDKs and APIs. Our document lifecycle technologies are backed by multiple patents and have been incorporated successfully into a wide range of applications. Our dedicated engineers provide ongoing support and work closely with customers to implement their specific use cases, ensuring that their software platform is delivering the best possible experience.
To learn more about integrating third-party software with Accusoft SDKs and APIs, talk to one of our solutions experts today.

An automated forms processing solution can significantly improve accuracy and efficiency when it comes to managing large quantities of documents containing structured content. Whether an organization needs to digitize existing records or is continuously processing new documents within application workflows, having a versatile optical character recognition (OCR) component working to identify and extract text from multiple languages allows them to capture data more effectively. Solid OCR form capture is critical.
Although a good OCR engine operates quickly and efficiently, the process of recognizing and extracting text is a highly complex undertaking that can be impacted by a variety of factors. Under optimal conditions, for example, the OCR component within Accusoft’s FormSuite can generate results quickly and accurately, with the ability to read several languages from around the world. However, if an application’s forms processing workflow is not set up efficiently or overlooks a few important considerations, recognition performance may suffer in terms of speed and accuracy.
6 Ways to Achieve the Best Results with the Accusoft OCR Component in FormSuite
1. Pay Attention to Image Resolution
As a general rule, OCR components should be provided with high resolution images so the recognition engine is able to distinguish the details that would otherwise be missed on low resolution images. This helps them to recognize the differences between “l” and “i” or “O” and “0” (zero), which results in better, more accurate results.
However, there could be a problem if the image resolution is too high. These images require much more time to process without delivering any benefits since the required letter properties are clearly distinguishable in a lower resolution.
To strike a balance between speed and accuracy, it’s better to scan all images in a 150-400 dots-per-pixel range. This allows the recognition engine to identify all possible letter properties and avoid being bogged down with analyzing a lot of data at the same time.
2. Don’t Lose Image Properties While Preparing to Recognize
To achieve the best results, it’s important to provide the recognition engine with a few helpful hints. In some cases, resolution properties may be lost while an image is being prepared for recognition, leading to worse than expected results. This happens most frequently when working with System.Drawing.Image or SystemDrawing.Bitmap classes directly during operations like clipping, merging, or reducing the bit depth.
In this case, the best solution is to make sure that HorizontalResolution and VerticalResolution properties are set correctly and reflect initial image resolution values. The ScanFix component within FormSuite can perform this task automatically and is designed to be compatible with the OCR component to help achieve better recognition results.
3. Clean Up Underlined Text Before Recognition
Specks, dirt, and other imperfections within the source image can significantly reduce recognition quality. Sometimes, however, even a seemingly good image can be recognized incorrectly when there are underlined words like URLs, emails, or specifically formatted generic text.
From the software’s point of view, this kind of text isn’t very different from other types of image distortion. ScanFix’s LineRemovalOptions can clean up the text by eliminating lines that could interfere with recognition. The API also features special parameters that ensures characters with low hanging elements (such as “j” or “y”) will be restored after line removal to avoid another potential recognition problem.
4. Use Long-Living Objects to Avoid Recognition Performance Drop
Creating a new instance requires OCR engine initialization and loading neural network data suitable for specific recognition parameters. This process is not resource free because of the data complexity and may cause delays from ~200 msec to 2 sec depending on the hardware and recognition properties.
Existing Accusoft OCR instances may be reused to recognize other images with different properties. This will speed up the overall process because initialization will be done only once during the first AnalyzeField call and subsequent calls will be much cheaper in terms of computing resources.
5. Assign Instances to Their Own Worker Threads
Objects are thread safe and can be called from different threads. However, assigning an object to its own thread can avoid extra locking. One of the simplest ways to do this is to use C# Parallel.ForEach loop and create ConcurrentQueue with the pre-allocated objects.
This ensures that the number of threads will not exceed the number of available CPUs. Any available instance can then be automatically assigned to recognize the images in their own thread while extra possible threads will wait until busy instances will be free to acquire.
Other common patterns are producer-consumer and map-reduce, which are more complex to implement but provide better flexibility when managing input data.
6. Dispose Objects to Avoid Memory High Memory Consumption
This is a generic rule for the C# to call a Dispose for the objects which use non-managed resources. FormSuite’s OCR component uses an external recognition engine, so it is highly recommended to call Dispose when the instance will not be required anymore. This can avoid a situation where the memory will not be available for different parts of the application, especially when a high amount of data exists for post-processing or the amount of available memory is low because of the different processes running in parallel.
Get Accurate OCR Data Capture Results with FormSuite
When properly configured and incorporated into a forms processing workflow, the FormSuite OCR component can accelerate automated data capture and reduce manual errors. Its zonal field recognition capabilities allow it to hone in on predefined field types to improve processing speed and accuracy. Developers can also adjust confidence values for recognition results to determine how frequently manual review is necessary.
To get a hands-on look at how FormSuite incorporates OCR seamlessly into its collection of forms processing tools, schedule a free trial today.

Today’s high-speed forms processing workflows depend on accurate character recognition to capture data from document images. Rather than manually reviewing forms and entering data by hand, optical character recognition (OCR) and intelligent character recognition (ICR) allow developers to automate the data capture process while also cutting down on human error. Thanks to OCR segmentation, these tools are able to read a wide range of character types to keep forms workflows moving efficiently.
Recognizing Fonts
Deploying OCR to capture data is a complex undertaking due to the immense diversity of fonts in use. Modern character recognition software focuses on identifying the pixel patterns associated with specific characters rather than matching characters to existing libraries. This gives them the flexibility needed to discern multiple font types, but problems can still arise due to spacing issues that make it difficult to tell where one character ends and another begins.
Fonts generally come in one of two forms that impact how much space each character occupies. “Fixed” or “monospaced” fonts are uniformly spaced so that every character takes up the exact same amount of space on the page. While not quite as popular now in the era of word processing software and digital printing, fixed fonts were once the standard form of typeface due to the technical limitations of printing presses and typewriters. On a traditional typewriter, for example, characters were evenly spaced because each typebar (or striker) was a standardized size.
From an OCR standpoint, fixed fonts are easier to read because they can be neatly segmented. Each segmented character is the same size, no matter what letters, numbers, or symbols are used. In the example below, the amount of space occupied by the characters is determined by the number of characters used, not the shape of the characters themselves. This makes it easy to break the text down into a segmented grid for accurate recognition.
“Proportional” fonts, however, are not uniformly spaced. The amount of space taken up by each character is determined by the shape of the character itself. So while a w takes up the same space as an i in a fixed font, it takes up much more space in a proportional font.
The inherent characteristics of proportional fonts makes them more difficult to segment cleanly. Since each character occupies a variable amount of space, each segmentation box needs to be a different shape. In the example below, applying a standardized segmentation grid to the text would fail to cleanly separate individual characters, even though both lines feature the exact same character count.
Yet another font challenge comes from “kerning,” which reduces the space between certain characters to allow them to overlap. Frequently used in printing, kerning makes for an aesthetically pleasing font, but it can create serious headaches for OCR data capture because many characters don’t separate cleanly. In the example below, small portions of the W and the A overlap, which could create confusion for an OCR engine as it analyzes pixel data. While the overlap is very slight in this example, many fonts feature far more extreme kerning.
In order to get a clean reading of printed text for more accurate recognition results, OCR engines like the one built into Accusoft’s SmartZone SDK utilize segmentation to take an image and split it into several smaller images before applying recognition. This allows the engine to isolate characters from one another to get a clean reading without any stray pixels that could impact recognition results.
Much of this process is handled automatically by the software. SmartZone, for instance, has OCR segmentation settings and properties that are handled internally based on the image at hand. In some cases, however, those controls may need to be adjusted manually to ensure the highest level of accuracy. If a specific font routinely returns failed or low confidence recognition results, it may be necessary to use the OCR segmentation properties to adjust for font characteristics like spaces, overlaps (kerning), and blob size (which distinguishes which pixels are classified as noise).
Applying ICR Segmentation
All of the challenges associated with cleanly segmenting printed text are magnified when it comes to hand printed text. Characters are rarely spaced or even shaped consistently, especially when they’re drawn without the guidance of comb lines that provide clear separation for the person completing a form.
Since ICR engines read characters as individual glyphs, they can become confused if overlapping characters are interpreted as a single glyph. In the example below, there is a slight overlap between the A and the c, while the cross elements of the f and t are merged to form the impression of a single character.
SmartZone’s ICR segmentation properties can be used to pull apart overlapping characters and split merged characters for more accurate recognition results. This is also important for maintaining a consistent character count. If the ICR engine isn’t accounting for overlapped and merged characters, it could return fewer character results than are actually present in the image.
Enhance Your Data Forms Capture with SmartZone
Accusoft’s SmartZone SDK supports both zonal and full page OCR/ICR for forms processing workflows to quickly and accurately capture information from document images. When incorporated into a forms workflow and integrated with identification and alignment tools like the ones found in FormSuite, users can streamline data capture and processing by extracting text and routing it to the appropriate databases or application tools. SmartZone’s OCR supports 77 distinct languages from around the world, including a variety of Asian and Cyrillic characters. For a hands-on look at how SmartZone can enhance your data capture workflow, download a free trial today.
Automated data capture tools are an essential feature of today’s business applications. Without the ability to quickly extract information from incoming forms and documents, organizations will struggle to keep their records, databases, and customer-facing software up-to-date. While software SDKs like Accusoft’s SmartZone can deliver powerful optical character recognition (OCR) and intelligent character recognition (ICR) to help applications accurately capture the information they need, these tools were not designed to operate in isolation. To get the best performance out of them, they need to be incorporated into a comprehensive and well-designed forms processing workflow.
Building an Efficient and Effective Forms Processing Workflow
Although data capture is often the primary objective of forms processing, a number of elements need to be in place for an application to be able to deploy SmartZone’s powerful OCR/ICR functionality. The first step involves the creation of form templates that can be used both for identifying incoming scanned forms and for defining field regions on the page from which data can be extracted. Building this library of templates provides a road map of sorts for the recognition process.
After form images are acquired, either from pre-existing digital documents or newly scanned images, they may need to be enhanced or cleaned up to ensure the best recognition results. Operations such as binarization, despeckling, deskewing, and line removal can all improve the data capture process, especially in the case of scanned documents. Older documents frequently include a great deal of image noise when scanned into digital format, which can make it difficult for an OCR/ICR engine to properly segment and read characters cleanly.
Once a form image has undergone enhancement, it can be matched and aligned with the correct template to ensure that the SmartZone recognition engine will be able to obtain a clean field clip. Scanned images can be overlaid via an alignment algorithm that performs minor adjustments to match it exactly with the correct template. This step is crucial because the data capture process is set up to read the field areas identified by the template rather than recalibrating for each form. If the alignment is off, the engine will not get a clean read of the characters, which could result in inaccurate recognition results.
After the form is identified and aligned, additional enhancement and cleanup operations can be performed on the specific areas of the form that contain information to be extracted. This typically means individual field areas where text or other characters have been entered. The locations to be cleaned up can be designated during the template creation process when data extraction zones are defined. In some instances, a processing workflow may skip the initial full-page enhancement and instead only perform clean-up on areas where data capture will be carried out. This approach is often more efficient from a processing standpoint, especially when targeted, zonal recognition is being applied.
Form image dropout can also be performed at this stage, which involves the removal of image content like signature lines, text field boxes, comb lines, or other extraneous guiding content. Here again, proper form alignment is crucial. If the form is slightly “off” from the template, valuable character content could be removed, making accurate recognition much more difficult. Good form dropout tools should also be able to reconstruct characters that lose pixel data during the dropout process, which is common for characters that have an element that overlaps form lines (such as the lower half of a “j” or a “y,” which might otherwise be read as an “i” or a “v” if not repaired prior to recognition).
SmartZone’s Role in the Recognition Phase of Application Workflows
After a form is acquired, enhanced, identified, and aligned, it can be passed along to the next stage of the workflow for text recognition using SmartZone OCR/ICR. There are a few options that can be selected at this point to help improve recognition accuracy and faster data capture performance.
1. Select Character Sets
SmartZone supports a wide variety of languages and alphanumeric character sets. Realistically, only a few of these sets will need to be used at any one time. Selecting only the sets needed for a particular form will improve recognition accuracy and speed. For instance, there’s no need to have support of Cyrillic languages (like Russian or Greek) enabled if all of the forms being processed are in English.
2. Designate Field Types
SmartZone can designate the expected format of text found in specific fields on a template. Rather than reading each field out of context and extracting the contents without knowing whether or not it’s been filled in correctly, field types can be set to values such as date, email, currency, phone number, or Social Security Number. Regular expressions can also be established for more customizable results. If the character content of the field doesn’t match the designated field type, SmartZone will immediately return an exception and move on rather than trying to recognize and extract the incorrect data. Setting this parameter can greatly improve both accuracy and speed.
3. Set Minimum Character Confidence
Every character SmartZone reads is assigned a confidence value, which reflects the OCR/ICR engine’s assessment of its recognition accuracy. A lower value means that there is a higher likelihood that a character was incorrectly identified. Setting a minimum character confidence value ensures that any character result below that value will be rejected and replaced with a designated rejection character. In practice, this control is used to determine which characters require a manual review following recognition. Setting a high confidence value will ensure higher recognition accuracy, but will likely lead to more exceptions that need to be reviewed by a human.
SmartZone Recognition Results
After character recognition is performed, results can be returned for the character, text line, or text block level. This data can then be passed along to the next stage of a business workflow or used to populate databases connected to the application. Operation instructions, identification, and image areas defined can be transferred to other components for additional forms processing or stored in memory for later access using SmartZone’s Read From Stream or Write From Stream functions.
Getting Started with SmartZone
With support for both OCR and ICR data capture, Accusoft’s SmartZone SDK can serve a vital role in high-performance forms processing applications. The powerful OCR engine can recognize multiple languages, including select Asian, African, and Indian characters. Capable of performing full page or zonal text extraction, SmartZone also includes a variety of customization features that can improve accuracy and recognition speed. Learn more about this versatile SDK’s features and use cases in our product fact sheet.

As a developer working with lenders, you strive to build an application that makes life easier for your clients. In the financial industry, processing data is essential. In order to process it efficiently, lenders must collect data from a variety of different forms. Whether consumers are coming to them for a loan, bank account, or credit card, lenders must gather a variety of personal information from them in order to approve or decline the request. Fintech form processing is a key capability for financial applications.
In an ever-changing digital landscape, financial institutions big and small are struggling to keep up with the instantaneous product offerings which consumers are coming to expect. This mindset is pushing lenders to reconsider their data gathering processes, searching for faster, more efficient solutions.
Challenges Facing Financial Forms Workflows
There are so many forms consumers must fill out to get approved for financial requests. Loan applications, in particular, can be daunting. Underwriters need everything from pay stubs and bank statements to documented work history and credit score reports. It’s a lot of information for lenders to sort through, especially considering that it comes in a variety of formats.
To make things even more complicated, not all of those documents arrive at the same time or from one source. A single loan application may have different forms trickling in over the course of several weeks. Whether the lender is processing that information as it comes in or storing files for review at a later date, it can be difficult to keep everything sorted properly.
But even after receiving the proper materials, the data scattered across several form fields in multiple documents needs to make its way from the page and into the lender’s databases and applications. Traditionally, that required painstaking manual data entry processes that were both slow and prone to error. While some firms have transitioned to purely digital portals that automatically transfer entered information to the proper destination, many still rely on form documents that are either filled out by hand or submitted in digital format.
For all the talk of organizations going paperless, many lenders still need to process a large number of paper forms, which will involve a combination of manual data entry and scanning documents into digital form. Even if they are set up to receive forms online, they may not have the right software tools in place to extract data from them efficiently or route them to the proper workflow destination. Here again, lenders can end up relying on manual data entry to fill in the gaps, which increases the likelihood that human error will contribute to delays and costly mistakes.
Building a Better Forms Processing Solution
FinTech developers can help lenders manage their form processing needs by designing automated workflows that can identify forms, capture data, and route files more efficiently. The process begins with good form identification capabilities that can match a broad range of documents to existing templates. Not only is this helpful when identifying documents received digitally, but it’s also extremely useful for managing physical documents once they’ve been scanned into the application. Rather than laboriously sorting through scanned files, an automated forms identification system can quickly match batches of documents to determine what kind of form information they contain and then pass them along to the next step of the workflow.
After the identification process, forms can then be aligned with the template to improve data capture accuracy. They could also be routed to the proper storage destination at that point if information doesn’t need to be extracted right away. When the time comes to capture form field content, optical character recognition (OCR) can be applied to documents to efficiently extract text and send it to various databases or other application tools. In the case of handprinted text, intelligent character recognition (ICR) can be used to accurately identify and capture data for processing. For forms with fillable information like bubbles or checkboxes, optical mark recognition (OMR) tools can quickly read which areas have been filled in without anyone having to manually review the document.
Of course, the entire identification and data capture process will go much smoother if the application managing forms is equipped with image cleanup tools that allow it to enhance document images and remove imperfections that might interfere with form processing. This not only includes deskewing and noise removal, but also form dropout capabilities which remove any template images that obscure or overlap with information that needs to be extracted.
Creating a Solution within Your Application
Your FinTech application already offers a variety of robust services for financial professionals, but integrating forms processing capabilities can make it even more attractive in a competitive market. Accusoft’s FormSuite Collection provides a comprehensive set of SDKs for processing standardized forms as part of an automated workflow. It’s the best way to integrate forms identification and data capture into your application without compromising your development timeline or sacrificing functionality.
In addition to an extensive array of image cleanup tools, the FormSuite Collection provides the FormFix component to allow applications to quickly match document images to whatever form templates an organization uses as part of its business processes. Documents can then be efficiently routed to wherever they need to be stored for easy retrieval in the future. FormFix can also perform image dropout and features OMR capabilities for accurate data capture.
The SmartZone component is also included in the FormSuite Collection, delivering powerful OCR and ICR features that can be customized for full page or zonal data capture. With support for multiple Western and Eastern languages, SmartZone has the flexibility to handle almost any documents that pass through FinTech workflows.
By integrating the FormSuite Collection into your application, you gain much more functionality for your product and your customers gain another benefit from your services. They’ll be saving time using your application – just like you’ll save time writing code. When your clients have the ability to process data faster, they win more business. Help your customers succeed, and remain their trusted partner for digital financial technology.
For more information on the FormSuite Collection, check out our comprehensive fact sheet. If you’re ready to see how FormSuite will look within your application environment, download a free trial today.

Rick Scanlan, Accusoft Director of Sales Engineering
Throughout time people have been looking for ways to gather information. The invention of the printing press allowed large-scale production of documents and printing of the earliest forms. Until the 1980s, information collected from forms was tabulated by hand or manually entered into a computer. Hand print recognition technology, more commonly known as Intelligent Character Recognition (ICR), has progressed significantly since that time, but the accuracy and productivity of forms processing is highly dependent on form design.
There are many factors to consider when designing a form to collect hand printed responses. First and foremost, the form needs to be easily understood by your target audience. The form also needs to constrain the response area and clearly identify where the user should write their responses.
Remember that the person filling out the form is usually out of your control. No matter how well you design your form, there will always be responses that can’t be read automatically. You can encourage the form fillers to write neatly, and keep their responses within the spaces allotted, but there will always be people who don’t read instructions (or ignore them) and assume that the form will be read by a human, not by a computer. They may do things like writing a character by mistake, then drawing a big “X” over it to “delete” it. Some people have poor handwriting, or always write in cursive.
Accuracy vs Confidence
Although they’re often used interchangeably, “accuracy” and “confidence” have two different meanings with regards to ICR software. Accuracy represents the percentage of actual text that is read correctly. Since character recognition applications don’t actually know when they misread a character, they cannot self-report accuracy. It can only be calculated after the recognition process by comparing the “ground truth” (the actual text) with the application’s reported recognition results.
“Confidence,” on the other hand, represents how certain the application is that it has identified a character correctly. Each character result generally has a confidence value ranging from 0 to 100, which can be calculated based upon a variety of recognition characteristics. Confidence values can also be returned for each line of characters or each field in a form in addition to each character individually.
If the ICR engine’s confidence does not exceed this value when reading a given character, it may reject the character and replace its text output with a placeholder until it can be reviewed manually. This is typically done when the engine is unable to determine what a pattern of pixels represents. Some engines (such as Accusoft’s SmartZone) can instead be configured to report the character result with the highest confidence or return a list of possible characters, each with individual confidence values. A final determination can then be made through human review or other data validation operations.
The industry accuracy average for ICR applications is about 70%. That means that three out of every ten characters are read incorrectly or aren’t recognized with a high enough confidence to be considered accurate. One should never expect 100% accuracy in any forms processing project, but a successful ICR application should exceed 70% accuracy. A rate of 85% or higher is considered good (although that’s still 15 bad characters out of every 100). With a little planning and some basic form design elements in place, however, you can usually exceed the 70% threshold.
In fact, since the way people fill out your forms has such a big impact on recognition results, taking small steps to improve compliance is immensely beneficial. Without changing any other aspects of your form, simply changing user instructions can provide a significant improvement in recognition rates.
5 Simple Ways Improve ICR Software Recognition Rates
- Tell the user that the form will be processed by a computer.
- Stress the importance of writing plainly, carefully, and clearly.
- Ask them to use block letters and avoid cursive handwriting.
- Put the instructions in bold at the top of the form, or just above the first field.
- Show character examples such as how an “A” or a “2” should be formed.
Field Design Considerations for ICR Software
Properly laying out the areas for printed responses can make the most significant impact in accurate hand print content recognition. A common mistake in field design is to provide a freeform area for a response. This design is often a simple blank line where people should write. Without any character restraints, people will write in cursive, run their characters together, write on top of the line, or write multiple lines in a single line response area. All of these factors will have a serious impact on intelligent text recognition accuracy.
A form needs to have a defined response area for each character, encouraging character separation. Some approaches for character separation work better than others, and are described below.
Comb Lines
Comb lines are horizontal lines with small vertical separators called tick marks. This is traditionally the most common type of hand print form design, often used in manual data entry applications. However, it’s not as well suited for automated ICR processing as other approaches. While the tick marks may encourage people to separate their characters, they rarely ever write the characters within each space. The spacing between the vertical lines on many forms is frequently too close together, making it almost impossible for the average person to stay between the lines. The height of the tick lines also plays an important role in encouraging character separation.
If you use comb lines, provide plenty of room between each of the vertical tick marks. Make the tick marks tall enough to encourage people to write between them. A vertical height at least half the height of the expected character is usually sufficient.
Example of a Poor Comb Line

Example of a Good Comb Line
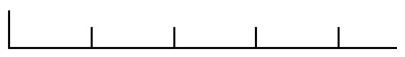
Character Boxes
Character boxes are usually the best method to encourage character separation. A good character box design will allow users to write their characters completely within each box. Unfortunately, many forms contain boxes that are too small and too close together. People often can’t write small enough to keep an entire character within a box. Pencil lead creates strokes that are usually much wider than with pens, making it even harder to constrain the character. The following are some general guidelines for designing character boxes.
Each box should be square in shape. Rectangular boxes with the height taller than the width can make the user feel like they need to squeeze their characters into the space. This often results in characters written in a compressed vertical form, reducing accuracy. A square shape encourages wider, more normally formed characters.
Narrow Boxes

Square Boxes

Single character response locations, such as for Male (“M”) or Female (“F”), should be provided in a single box separated from other responses.
Multiple character response locations, such as a Name field, may contain separated boxes if space permits.

They could also be joined together when space is a consideration. If joined, a thick separator between the response locations, at least one-fourth the width of a response area, should be used to discourage characters entering other boxes.

Individual fields should be separated by enough space to easily identify where one field stops and the next starts. Spacing of at least 1.5 box widths is recommended to prevent users from interpreting the space as a valid character location.

Rows of fields stacked vertically should be separated by at least one half the height of an individual box.

Boxes can be printed with either solid black lines or dropout colors, depending on the scanning and forms processing technology used. Some forms processing technology, such as Accusoft’s FormSuite software development kit (SDK), best performs form identification and alignment when all boxes and form contents are retained. Software-based form dropout is used to remove the boxes from the image after scanning. The original image with boxes intact may then be archived for future reference.
Several forms processing systems require dropout colors to be used when printing forms. For example, a form is printed in red ink, and a red bulb in the scanner eliminates the red content when the image is captured. Unlike these types of forms processing technology, the FormSuite SDK doesn’t require any special printing, paper, or inks. It provides much greater printing flexibility and reduced printing costs. The use of general purpose scanning technology without requiring special bulbs may also reduce capital costs.
Paper Thickness and Bleed-Through
The quality of paper can impact recognition accuracy in dual-sided forms. Form paper should be thick enough to prevent the back side content from bleeding through when scanned. Fields on form fronts and backs may also be offset to ensure that any bleed-through content from one side will not interfere with field recognition on the other.
Example of Bleed Through

Processing a Hand Print Form
Intelligent character recognition accuracy can often be increased through image enhancement and other pre-processing activities. Many scanners today include image enhancement technologies that will create a good representation of the original image. This enhanced image may work well for viewing or archival purposes, but it may not be the best to use for content recognition. Lines or boxes in the image may interfere with field recognition. Dot shaded fields may prevent easy recognition of filled content. Filled forms might be received via fax at a low resolution, where built-in image enhancement is not available. The use of post-scan image enhancement processes can significantly improve forms processing and intelligent text recognition.
A temporary copy of the image can be created solely for use with the ICR application. Enhancements are performed that directly impact recognition. If poor recognition results are received, additional enhancements may be performed, looping through a series of “enhance – attempt to recognize – enhance – attempt to recognize” processes until the field is read with high confidence or a decision is made to route the image for manual data entry. Once recognition is complete, the temporary image is deleted and the original image is archived.
Certain enhancement processes are specifically designed to improve character recognition, especially when you don’t have control over the form design. For example, forms that contain shaded fields in response areas can be very difficult to recognize. Dot shading removal with character smoothing can significantly improve recognition of those fields.
Software-based form dropout—removal of background form content—can allow recognition of content that has been written over master form elements. For example, users completing forms with comb lines often write on top of the lines, resulting in very difficult recognition. An automated comb line removal process will remove the comb lines and reconstruct the intersecting characters, allowing for accurate recognition.
Before Comb Removal
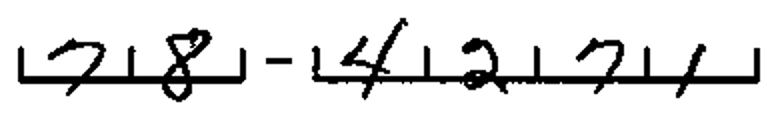
After Comb Removal, with Character Repair
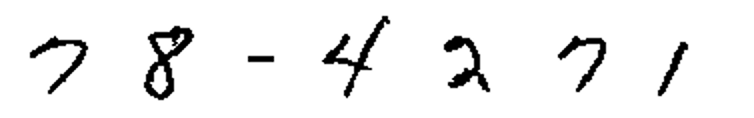
Improve ICR Application Performance with Focused Recognition and Data Validation
Some fields are designed to allow only certain characters to be entered. For example, a date field may allow only digits, or only digits, dashes, and slashes. A “Male/Female” field may only allow the characters M and F. Ensure that your form contains instructions or examples for each field to ensure the user knows what characters are allowed. ICR technology such as Accusoft’s SmartZone ICR/OCR component allows definition of allowable characters, increasing accuracy by focusing the recognition engine towards specific characters.
Remember that the industry average for hand print recognition is only 70%. Data validation and correction is critical to a successful hand-printed forms recognition system. Use recognition confidence values to locate suspect characters. Use two or more ICR engines in a voting process, comparing the results from each engine to determine the highest confidence results. Recognized data should be compared against database tables, dictionaries, lookup tables, or other data validation tools.
A “key from image” process is typically required to validate low confidence data. You should develop a process to display suspect characters or fields to a human for manual data entry. Human interaction is the most expensive part of any data capture process, so any efforts you can take, such as strong form design or additional image enhancement processes, will easily pay for themselves when compared to the cost of manual data entry.
Test Your Form
It’s critical to develop a prototype of your form then test it on a sampling of actual users. Present the form to people who have not seen any previous versions and ask them to complete it. Statistical sampling and analysis is helpful when testing forms that will be used on a large scale. Forms for smaller audiences do not require scientific analysis. Just be sure that you employ representative users in the test.
You should also test your recognition processes with enough sample data to get a good sense of the results. Identify weaknesses in the form or recognition, make changes, then retest to confirm improved results.
A Note About OMR
Optical Mark Recognition (OMR), sometimes known as “mark sense,” is the analysis of form locations to determine if a mark is present. Examples of OMR zones include check boxes on a form to designate male or female, multiple choice responses on a high-stakes educational exam, or diagnosis results on a medical form. The OMR response areas may be a single box, multiple response zones such as a “check all that apply” field, or a true/false designation.
Many forms contain some type of OMR field. Designing an OMR field is simpler than for character recognition, but still requires careful consideration. Whether you use an oval bubble, square box, or open brackets, be sure the area is large enough for the user to easily mark within the designated space.
Common OMR field design errors include making the box too small for people to easily mark within the zone, or printing the boxes too close together, resulting in more than one box containing the mark. Some users will circle an OMR response area instead of filling in the box. Similar to character responses, providing clear instructions and example marks can significantly improve recognition results. Even great instructions will not prevent some people marking a zone in error then drawing a big “X” over in an attempt to “delete” the mark. Business rules must be developed to handle multiple mark situations and manual key-from-image operations are usually required to determine user intent.
In Conclusion
Many factors influence the accuracy and success of a hand print forms processing system. The extra time and consideration spent in forms design will pay strong dividends in recognition accuracy and reduced costs for manual data entry. Carefully consider your target audience to design a form that will be easily understood and completed, and can be easily recognized and processed by ICR software.
Rick Scanlan joined Accusoft with the acquisition of TMSSequoia in December 2004. With 27 years of experience in the document imaging market, Rick has served in a variety of technical, business development, and corporate management roles. He has developed extensive expertise in a wide variety of imaging technologies including document viewing, information capture, image enhancement, and forms processing. Rick currently manages Accusoft’s sales engineering/pre-sales team and helps define Accusoft’s product strategy and future development. A native of Oklahoma, he earned Bachelor of Science degrees from Oklahoma State University in Business Management, Economics, and Management Science and Computer Systems.

When the time comes to extract data from standard forms, simply scanning the entire document isn’t an ideal solution. This is especially true of forms that include instructional text, since you probably don’t want to keep capturing “Directions” from every form. Even when looking only at fillable information, there can be a lot of text to capture. Optical character recognition makes it simple to automate data extraction as part of a forms processing workflow, but the most effective frameworks utilize a specialized form of recognition known as zonal OCR.
What Is Zonal OCR?
While zonal OCR still identifies machine-printed text and matches it to existing character sets before handing it off to another stage of a predetermined workflow, what sets the process apart is the way it goes about reading a document page. A typical standard form often features multiple fillable boxes where someone can enter their information. It could also include drop-down menus with predetermined responses (suffix, state, and country are all common examples of this). Trying to recognize all of that text at once greatly increases the number of possible results, which could impact both accuracy and performance.
Zonal OCR addresses this challenge by splitting the page up into several distinct zones, each of which typically corresponds to a form field (although it doesn’t have to). Instead of reading the entire page, then, the OCR engine selectively recognizes the text in these zones. It can also be combined with form image dropout, which removes text and graphical elements that don’t need to be read and might interfere with the recognition process. By reducing the amount of text that needs to be matched, zonal OCR and significantly improve recognition speed and accuracy.
Limiting Recognition Results
The most effective OCR solutions then go a step further by designating the type of information that should be found within those zones. This reduces the range of potential outcomes, which makes it easier for the OCR engine to return an accurate reading.
For example, the letter “Z” bears superficial similarities to the number “2.” If the OCR engine needs to take into account all possible responses, it may struggle to distinguish between the two accurately, especially if an unusual font was used to complete the form. However, if developers stipulate that a particular “zone” should only include numerical values, the OCR engine suddenly goes from having to consider dozens of letters and special characters to just ten numbers. This makes it much easier to obtain an accurate recognition result.
For hand-printed form responses, applying the same zonal strategy to Intelligent Character Recognition (ICR) is especially helpful. Going back to the “Z” and “2” example, the distinctions between the two characters are often much more subtle in the case of hand-printing. If a form field includes the date to be printed out in a month/day/year format, there is no reason to include a “Z” in the list of potential characters that might be found in that field because no month includes a “Z.” When the ICR engine comes across a “2,” then, it’s more likely to identify it correctly because there are fewer potential alternative characters.
By constraining possible recognition results over a smaller range of defined character sets, zonal OCR and ICR both greatly improve accuracy when it comes to forms processing. The list of potential results is typically referred to as a data validation list.
In addition to constraining character sets, regular expressions can also be applied to different zones to specify what kind of data is expected to be found there. A regular expression is simply a string pattern that sets rules for how characters are formatted, such as a phone number, Social Security number, or credit card number.
Setting Up Zonal OCR
Integrating zonal OCR capabilities into a forms processing workflow first requires the creation of specialized templates that map out the location of each field that contains data. In any organization, the various types of standard forms received should always be built as templates within the solution. This allows the application to both match incoming forms to existing templates, but also align them to ensure that everything is in the proper location.
The alignment step is extremely important for effective data extraction. Zonal OCR is set up to read only specific areas on a document page. These zones have clear boundaries, and anything caught outside that boundary will not be read while any character that’s only partly within the field will likely return an error result of some kind.
Accusoft’s SmartZone OCR/ICR integration, for instance, works most effectively when paired with the FormFix SDK, which handles form template creation, identification, and alignment. As part of the broader FormSuite solution, these integrations are extremely effective when it comes to streamlining data capture.
Improve Data Capture Accuracy with SmartZone
With OCR and ICR support for multiple languages, SmartZone is a powerful data extraction tool that can be incorporated into an application individually or with the rest of the FormSuite collection. It provides fast, accurate text recognition on both a zonal and a full-page basis. Developers can set up expected character patterns for fields and designate different regular expressions for all of them to deliver results that are significantly more accurate.
SmartZone not only provides out-of-the box support for pre-defined character sets, such as upper and lower case characters, arithmetic symbols, and currency symbols, it also allows developers to edit those sets to improve accuracy, confidence, and speed.
Find out how the SmartZone OCR/ICR can enhance your application’s forms processing data extraction today by downloading a free trial.

The days of manually transcribing scanned documents into an editable, digital document are thankfully long behind most organizations. Error-prone manual processes have largely given way to automated document and forms processing technology that can turn scanned documents into a more manageable form with a much higher degree of accuracy.
Much of transition was made possible by the proliferation of optical character recognition (OCR) and intelligent character recognition (ICR). While they perform very similar tasks, there are some key differences between them that developers need to keep in mind as they build their document and form processing applications.
How Does Character Recognition Technology Work?
Character recognition technology allows computer software to read and recognize text contained in an image and then convert it into a document that can be searched or edited. Since the process involves something that humans can do quite easily (namely, reading text), it’s easy to assume that this would be a rather trivial task for a computer to accomplish.
In reality, getting a computer program to correctly identify text and convert it into editable format is an incredibly complex challenge complicated by a wide range of variables. The problem is that when a computer examines an image, it doesn’t see people, backgrounds, or text as distinct images, but rather as a pattern of pixels. Character recognition technology helps computers distinguish text by telling them what patterns to look for.
Unfortunately, even this isn’t as straightforward as it sounds. That’s because there are so many different text fonts that depict the same characters in different ways. For example, a computer must be able to recognize that each of the following characters is an “a”:
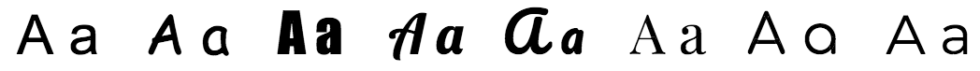
When humans read text, they have a mental concept of what the letter “a” looks like, but that concept is incredibly flexible and can easily accommodate a broad range of variations. Computers, however, require precision. Programmers must provide them with clear parameters that help them to navigate unexpected variations and identify characters accurately.
Pattern Recognition
The earliest versions of character recognition developed in the 1960s relied on pattern recognition techniques, which scanned images and searched for pixel patterns that matched a backlog of font characters stored in memory. Once those patterns were located, the software could translate the characters into searchable, editable text in a document format. Unfortunately, the patterns had to be an exact pixel match, which severely limited how broadly the technology could be applied.
One of the first specialized fonts developed to facilitate pattern recognition was OCR-A. A simple monospace font (meaning that each character has the same width), OCR-A was used on bank checks to help banks quickly scan them electronically. Although pattern recognition libraries expanded over the years to incorporate common print fonts like Times New Roman and Arial, this still presented serious limitations, especially as the variety of fonts continued to grow. With one popular font finding website indexing more than 775,000 available fonts in 2021, pattern recognition needed to be supplemented by another approach to character recognition.
Feature Detection
Also known as feature extraction, feature detection focuses on the component elements of printed characters rather than looking at the character as a whole. Where pattern recognition tries to match characters to known libraries, this approach looks for very specific features that distinguish one character from another. A character that features two angular lines that come to a point and are crossed by a horizontal line in the middle, for instance, is almost always an “A,” regardless of the font used. Feature detection focuses on these qualities, which allows it to identify a character even the program has never encountered a particular font before. As the printed examples above demonstrate, however, this approach needs to take several ways of rendering the character “A” into consideration when setting parameters.
Most character recognition software tools utilize feature detection because it offers far more flexibility than pattern recognition. This is especially valuable for reading document images with faded ink or some degradation that could prevent an exact pattern match. Feature detection provides enough flexibility for a program to be able to identify characters under less than ideal circumstances, which is important for any application that has to deal with scanned images.
OCR vs ICR: What’s the Difference?
Optical character recognition (OCR) is typically understood to apply to any recognition technology that reads machine printed text. A classic OCR use case would involve reading the image of a printed document, such as a book page, newspaper clipping, or a legal contract, and then translating the characters into a separate file that could be searched and edited with a document viewer or word processor. It’s also incredibly useful for automating forms processing. By zonally applying the OCR engine to form fields, information can be quickly extracted and entered elsewhere, such as a spreadsheet or database.
When it comes to form fields, however, information is frequently entered by hand rather than typed. Reading hand-printed text adds another layer of complexity to character recognition. The range of more than 700,000 printed font types is insignificant compared to the near infinite variations in hand-printed characters. Not only must the recognition software account for stylistic variations, but also the type of writing implement used, the quality of the paper, mistakes, steadiness of hand, and smudges or running ink.
Intelligent character recognition (ICR) utilizes constantly updating algorithms to gather more data about variations in hand-printed characters to identify them more accurately. Developed in the early 1990s to help automate forms processing, ICR makes it possible to translate manually entered information into text that can be easily read, searched, and edited. It is most effective when used to read characters that are clearly separated into individual areas or zones, such as fixed fields used on many structured forms.
Both OCR and ICR can be set up to read multiple languages, although limiting the range of expected characters to fewer languages will result in more optimal recognition results. Critically, ICR does not read cursive handwriting because it must still be able to evaluate each individual character. With cursive handwriting, it’s not always clear where one character ends and another begins, and the individual variations from one sample to another are even greater than with hand-printed text. Intelligent word recognition (IWR) is a newer technology that focuses on reading an entire word in context rather than identifying individual characters.
To learn more about how OCR vs ICR technology and how they can transform your application when it comes to managing documents and automated forms processing, download our whitepaper on the topic today.
So you’ve tried out our SDKs and you’re ready to install the license. The problem? You’re not sure how to get started. Accusoft offers a number of different license types based on customer need and environment. The following will show you how to install licenses for both evaluation and deployment depending on your specific needs.
The Basics on Activating Your Development License
The development machine licensing allows you to develop your applications without receiving evaluation prompts during runtime. To activate your license on your development machine, you will need to use the License Manager. Activating your license is simple. Just log into the License Manager using your account information and then click Activate.

Also, make sure to comment out any licensing calls in your code so that the toolkit will not look for a deployment license on the machine. When you’re ready to deploy your application, you have three different options for deployment: Node-Locked, OEM, and Web‑OEM. Our sales team can work with you on finding the right licensing for your project. Ready to get started?
Evaluation Licensing
During evaluation of Accusoft products, Evaluation licenses can be used to try out products. This license permits an Accusoft product or toolkit to be used on a system, whether it is a development machine or any other type of system. This type of license is best noted by an Evaluation dialog displaying occasionally while the product is in use.
Once the Evaluation dialog is dismissed, the product will continue to operate. Other forms of Evaluation or trial behavior include the watermarking of images when displayed or saved. When an Accusoft product is first installed onto a system, if no other license currently exists on the machine (and no other license is provided by the user during the installation), an Evaluation license will be placed on the system by default.
Interested in a more permanent licensing solution? Here are some instructions for installation for various scenarios.
Development SDK Licensing
As a precursor, Accusoft software is limited for use on a single CPU. Any runtimes or copies installed or distributed must be granted by a direct license from Accusoft. The first thing you’ll want to do is check your customer portal to make sure that you have an SDK license available.

Next, make sure there are no active license calls in your code (comment out any calls using a solution name, solution key, and OEM license key). When the license calls are active, the toolkit will be expecting a deployment license to be on the machine – which will fail since only a development license is on the system. When the licensing calls are not being used, the toolkit will automatically look for a development license.

You’ll want to make sure that there are no calls to SetSolutionName, SetSolutionKey, or SetOEMLicenseKey in your code. This ensures that no keys are pulled from your deployment pool.
Next, we’ll open the License Manager and log in.

Select a toolkit under the “Purchased Toolkit” section in the License Manager and click Activate on the right side of the dialog.

Once this is done, you can run your project and you won’t receive any licensing prompts. Your development machine is now licensed.
Deployment Runtime Licensing Overview
Node-locked licensing is designed for when your applications will run on a relatively small number of machines. Each of the machines will be assigned a license that is tied to the system’s hardware.
Once the license is applied, it cannot be removed. If a machine is being removed from service, please contact our sales department, who can assist with obtaining new licenses. You can license deployment machines programmatically (by using the LDK component) or by using the Server License Utility (SLU) provided with the SDK. In your code, you will call SetSolutionName and SetSolutionKey.

An OEM key unlocks the toolkit for use on many machines. With this key, there is no need to run the license utility and the license is not tied to any hardware. You can just throw it in your code and you can deploy without worrying about licensing individual machines.

The Web‑OEM key is used when embedding our ActiveX controls on your web page and is used to license client machines in the web application. The license is applied similarly to regular OEM with a SetSolutionName, SetSolutionKey, and SetOEMLicense key. When you purchase this license model, your OEM key will be web‑enabled.
Node-Locked Licensing
There are two methods you can use to register a runtime node‑locked license. SLU, the Server License Utility, and LDK, the License Deployment Kit. Both of these methods perform the same function of registering the runtime node‑locked license. The only difference is that the SLU provides a user interface for the LDK.
If you wish to hide the license registration from your end user, you will likely want to use the License Deployment Kit, which allows you to integrate the registration process in your application. Please note that when installing the license, the user that you’re running as must have administrative rights in order to add the key to the registry.
You will need a license configuration file for the SLU or LDK to activate licenses. The license configuration file contains information about runtime licenses for a particular platform, a version of a toolkit, and it can be downloaded from your Accusoft customer portal. Next, you will need to register your SLU if you’re planning to use the Server License Utility. The instructions are in the ReadMe file.

You’ll want to run the command prompt in administrative mode. Navigate to the location containing the Accusoft license client DLL. Once the DLL is registered, we can run the SLU. Here, we’re adding the config file that was downloaded. It gives us the option to auto‑register. This is available when you have an online connection, or manual register. When the computer is offline, you can do a manual registration. Here, we’re going to do the auto‑registration.
If licensing fails to register, you will receive an error message and a 14‑day temporary license will be applied, allowing you time to get the licensing issue resolved. If the license succeeds, your application should run without issues. As mentioned earlier, if your computer is offline, meaning that it has no Internet access, you can register using the manual registration process.

In this case, you will want to copy the hardware key and URL to a removable media device such as a thumb drive, and then, take it to a system that is connected to the Internet. From the connected system, paste the URL into the browser. A page will appear that contains a field into which you will enter the hardware key. After this hardware key is entered, a license file with a license key is downloaded, which you then save to the removable media, and take it to your offline system. Place your key in the SLU and click the license button to register your offline machine.
Once you’ve completed either process, your machine is licensed.
OEM Licensing
OEM licensing is ideal when deploying to many workstations or servers that have no Internet access. It provides an easier means of licensing for when your application runs in a secure environment. Accusoft’s OEM licensing is not tied to a specific computer and offers a quick and easy way to get your application licensed and ready for deployment.

First, if you haven’t already, you will want to obtain your license information from your customer portal. To apply an OEM license, simply add the solution name, solution key, and OEM key to your solution. It’s important that this information is placed before the usage of the toolkit within your project. Otherwise, when the application runs, you will see the licensing prompt. Now, we’ll run the application, and you see that the prompts to install the license are now gone.
Web OEM Licensing
If you’re using our ActiveX toolkits and you would like to embed them in your web page for running in a browser, you will need to use a special OEM license that’s intended for this type of deployment. To obtain a Web OEM license, please contact our sales department. They will provide you with access to a special site for generating Web OEM keys.
Once you access this site, you will enter the domain of your website where your web page will be hosted as well as the associated license information provided by our sales department. This will generate an OEM key, which you will be able to use on your web page.
In your web page’s scripting code, you will need to call the SetSolutionName, SetSolutionKey, and SetOEMLicenseKey functions, respectively, providing the license information for that toolkit. With this information in place, you can host your web page, and the ActiveX control will be licensed.

If this fails, however, then you might see a license error dialog display. Make sure that you’re using an actual license that was generated from the Web OEM license generator website provided by our sales department per your purchase.
If you need specific directions for licensing a particular SDK, please view the product on the Accusoft website and select documentation under the reference drop-down menu. For all of your other licensing questions, please contact a sales representative at info@accusoft.com or call us +1-800-875-7009 nationwide or +1-813-875-7575 international.